Why hexagonal architecture doesn’t suit me. My DDD implementation is a layered block architecture
* In this article, examples will be in TypeScript
Brief preface
What is DDD (Domain Driven Design) is an extensive question, but in short (as I understand it) it is about transferring business logic, as it is, into code, without going into technical details. That is, ideally, a person who knows about business processes can open the code and understand what is happening there.
All this is accompanied by a bunch of different recommendations for the technical implementation of the issue.
For a better understanding of the article, I advise you to read the materials related to DDD.
Hexagonal architecture is one approach to implement DDD.
Many advanced developers are familiar with the concept of hexagonal architecture.
I will not describe more specifically, the Habré is full of articles on this topic, everything has long been chewed up and practically digested.
Instead, I’ll show you a picture (img. 1):

Please tell me what you understand from this picture?
For example, when I first saw her, absolutely everything was incomprehensible to me.
And, as funny as it is, this is the first problem for me.
Visualization should provide insight, not add questions.
In the course of the study, everything partially falls into place, but questions and problems remain.
And then I thought about the application in general, developing ideas from DDD in general and hexagonal architecture in particular.
What we have:
- Real life. There are business processes here that we need to automate.
- An application that solves problems in real life, which in turn is not in a vacuum. The app has:
- — Users, be they APIs, crowns, user interfaces, etc.
- — The application code itself.
- — Data objects — DB, other API.
The movement goes first from top to bottom, then back, that is:
- Real-life subjects interact with the application, the application code interacts with data objects, then receiving a response from them, returns it to users.
Everything is logical.
Now let’s dive into the application code.
How to make the code understandable, testable, but at the same time as independent as possible from external data objects such as databases, APIs, etc.?
In response to this question, the following scheme was born (img. 2):
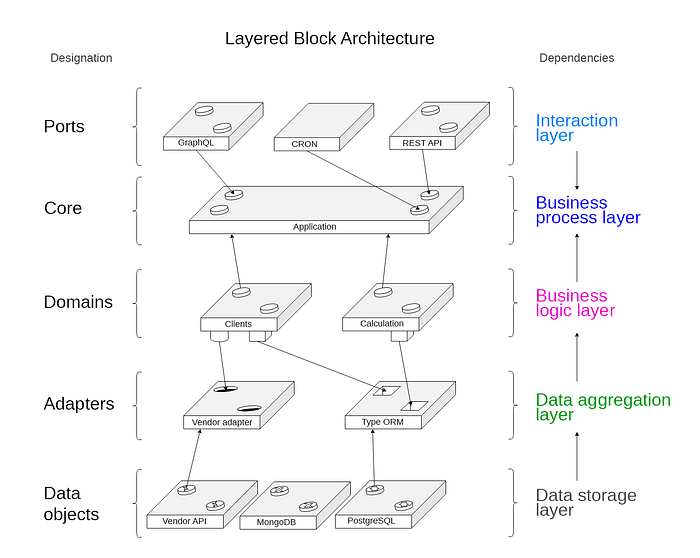
What we see here is very similar to hexagonal architecture, but unlike it, the logic is not closed in a hexagon or circle, as in onion architecture, but is simply scattered across levels, maintaining a logical chain of interactions described above — the request comes from above, goes down , then hops back up, returning the result.
Another difference is that a business process layer has been added, which will be discussed below.
Layered block architecture
Let’s go over the scheme.
In the image (img. 2), on the left, we see the names of entities, on the right — the purpose of the levels and their dependence on each other.
Top down:
- Ports — the level of interaction that depends on the level of business processes. The layer is responsible for interacting with the application, that is, it stores controllers. The application can only be used through the ports.
- The Core of the application — the level of business processes, is the center of all dependencies. The entire application is built on the basis of business processes.
- Domains — are a level of business logic that depends on the level of business processes. Domains are formed and built on the basis of the business processes that we want to automate. Domains are responsible for specific business logic.
- Adapters — are the data aggregation layer that depends on the business logic layer. Above gets the data interfaces that must be implemented. Responsible for getting and normalizing data from data objects.
- Data objects — are a layer of data storage that is not included in the application, but since the application does not exist in a vacuum, we must consider them.
A few rules
In the course of practice, several rules were born that allow maintaining cleanliness, simplicity and universality of the code:
- Business processes must return an unambiguous answer. For example, creating a client, if you have an affiliate program. You can make a business process that creates a client, and if he has a partner code, he also adds it to partners, but this is not correct. This approach makes your business processes opaque and unnecessarily complex. You must create 2 business processes — customer creation and partner creation.
- Domains should not communicate directly with each other. All communication between domains takes place in business processes. Otherwise, domains become interdependent.
- All domain controllers should not contain business logic, they only call domain methods.
- Domain methods should be implemented as pure functions, they should not have external dependencies.
- For methods, all incoming data must already be validated, all the necessary parameters must be required (data-transfer-objects or just DTOs will help here).
- For unit testing of a level, a lower level is needed. Injection (DI) is performed only at the lower level, for example, you test domains → replace adapters.
How is development going according to this scheme
- Business processes that we want to automate are highlighted, we describe the level of business processes.
- Business processes are broken down into chains of actions that are associated with specific areas (domains).
- We decide how we store data and with which external services we interact — we select adapters and data sources that our adapters support. For example, in the case of a database, we decide to store our data in a relational database, we look for an ORM that can work with them and at the same time meets our requirements, then we select a database for it, with which our ORM can work. In the case of external APIs, you will often have to write your own adapters, but again with an eye on domains, because the adapter has 2 main tasks: to receive data and send it up to the required domain in an adapted form.
- We decide how we interact with the application, that is, we think over the ports.
A small example
We want to make a small CRM, we want to store data in a relational database, we use TypeORM as an ORM, and PostgresSQL as a database.
Not all server code will be shown, but only the main points that you can apply in your application right now
To begin with, we implement the business process of creating a client.
Let’s prepare the folder structure:
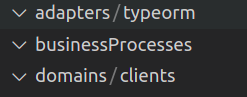
For convenience, let’s add aliases:
@clients = src/domains/clients@clientsEnities = src/adapters/typeorm/entities/clients@adapters = src/adapters
What a business process consists of in its simplest form:
- at the entrance we receive data about the client
- we need to save it to the DB
After talking with a domain expert, we find out that in addition to the general data of the client, he may have various contact information.
We form domain models that our adapters must implement. In our case, these are 2 models: client and contact information
domains/clients/models/Client.ts
import { Contact } from './Contact';
export interface Client {
id: number;
title: string;
contacts?: Contact[];
}domains/clients/models/Contact.ts
import { Client } from './Client';
export enum ContactType {
PHONE = 'phone',
EMAIL = 'email',
}
export interface Contact {
client?: Client;
type: ContactType;
value: string;
}We create a TypeORM entity for them.
adapters/typeorm/entities/clients/Client.ts
import { Column, Entity, OneToMany, PrimaryGeneratedColumn } from 'typeorm';
import { Client as ClientModel } from '@clients/models/Client';
import { Contact } from './Contact';
@Entity({ name: 'clients' })
export class Client implements ClientModel {
@PrimaryGeneratedColumn()
id: number;
@Column()
title: string;
@OneToMany((_type) => Contact, (contact) => contact.client)
contacts?: Contact[];
}adapters/typeorm/entities/clients/Contact.ts
import { Column, Entity, ManyToOne, PrimaryGeneratedColumn } from 'typeorm';
import { Contact as ContactModel, ContactType } from '@clients/models/Contact';
import { Client } from './Client';
@Entity({ name: 'contacts' })
export class Contact implements ContactModel {
@PrimaryGeneratedColumn()
id: number;
@Column({ type: 'string' })
type: ContactType;
@Column()
value: string;
@ManyToOne((_type) => Client, (client) => client.contacts, { nullable: false })
client?: Client;
}I will immediately explain why the fields with links are marked as optional: the data are in different tables, they always have to be requested. You can, of course, make them mandatory, but if you forget to request additional data somewhere, you will get an error.
Let’s implement the domain method for creating a client and a domain controller.
domains/clients/methods/createClient.ts
import { Repository } from 'typeorm';
import { Client as ClientModel } from '@clients/models/Client';
import { Client } from '@clientsEnities/Client';
export async function createClient(repo: Repository<Client>, clientData: ClientModel) {
const client = await repo.save(clientData);
return client;
}domains/clients/index.ts
import { Connection } from 'typeorm';
import { Client } from '@clientsEnities/Client';
import { Client as ClientModel } from '@clients/models/Client';
import { createClient } from './methods/createClient';
export class Clients {
protected _connection: Connection;
constructor(connection: Connection) {
if (!connection) {
throw new Error('No connection!');
}
this._connection = connection;
}
protected getRepository<T>(Entity: any) {
return this._connection.getRepository<T>(Entity);
}
protected getTreeRepository<T>(Entity: any) {
return this._connection.getTreeRepository<T>(Entity);
}
public async createClient(clientData: ClientModel) {
const repo = this.getRepository<Client>(Client);
const client = await createClient(repo, clientData);
return client;
}
}Because TypeORM is a bit of a specific library, inside we throw (for DI) not specific repositories, but a connection, which we will replace during tests.
It remains to create a business process.
businessProcesses/createClient.ts
import { Client as ClientModel } from '@clients/models/Client';
import { Clients } from '@clients';
import { db } from '@adapters/typeorm'; // I am stacking a TypeORM connection into a db object
export function createClient(clientData: ClientModel) {
const clients = new ClientService(db.connection)
const client = await clients.createClient(clientData)
return client
}In the example I will not show how to implement ports, which are in fact simple controllers that call certain business processes. Here you yourself somehow.
What does this architecture give us?
- A clear and convenient structure of folders and files.
- Convenient testing. Since the whole application is divided into layers — select the desired layer, replace the lower layer and test.
- Convenient logging. The example shows that logging can be built into every stage of the application’s operation — from the banal measurement of the execution speed of a specific domain method (just wrap the method function with a wrapper function that measures everything), to complete logging of the entire business process, including intermediate results.
- Convenient data validation. Each level can check data that is critical for itself. For example, the same business process of creating a client for good, in the beginning, should create a DTO for the client model, which validates the incoming data, then it should call a domain method that will check if such a client already exists and only then will create a client. I’ll tell you right away about access rights — I believe that access rights are an adapter, which you must also pass when creating a domain controller and check the rights inside the controllers.
- Easy code change. Let’s say I want to create an alert after creating a client, that is, I want to update the business process. I go into the business process, at the beginning I add the initialization of the notifications domain and after receiving the result of creating a client I do
notifications.notifyClient ({client: client.id, type: ’SUCCESS_REGISTRATION’})That’s all, I hope it was interesting, thanks for your attention!
